Revolutionizing Test Automation : The Power of Playwright AI Test Agents
Explore how Playwright v1.56 is transforming the automation landscape. Learn how AI Test Agents move beyond simple record-and-playback to provide self-healing, autonomous testing cycles that eliminate the heavy 'maintenance tax' on engineering teams
- The Dawn of Agentic Testing : Beyond Simple Record-and-Playback
In the current automation landscape, most teams are struggling under a significant "maintenance tax," where up to 20% of engineering time is lost to repairing fragile scripts rather than building new features. This overhead often results in "vibe coding" the use of AI to generate quick, unstructured scripts that lack the deterministic reliability required for production-grade pipelines.
The release of Playwright v1.56 marks a strategic shift from manual scripting toward a native ecosystem of Agentic workflows. These agents are not mere plugins; they are integrated components designed to bridge the gap between rapid test creation and long-term maintainability. By shifting the focus from "writing code" to "defining intent," these agents aim to eliminate the manual labor associated with traditional end-to-end testing while preserving the rigor expected by staff-level engineers.
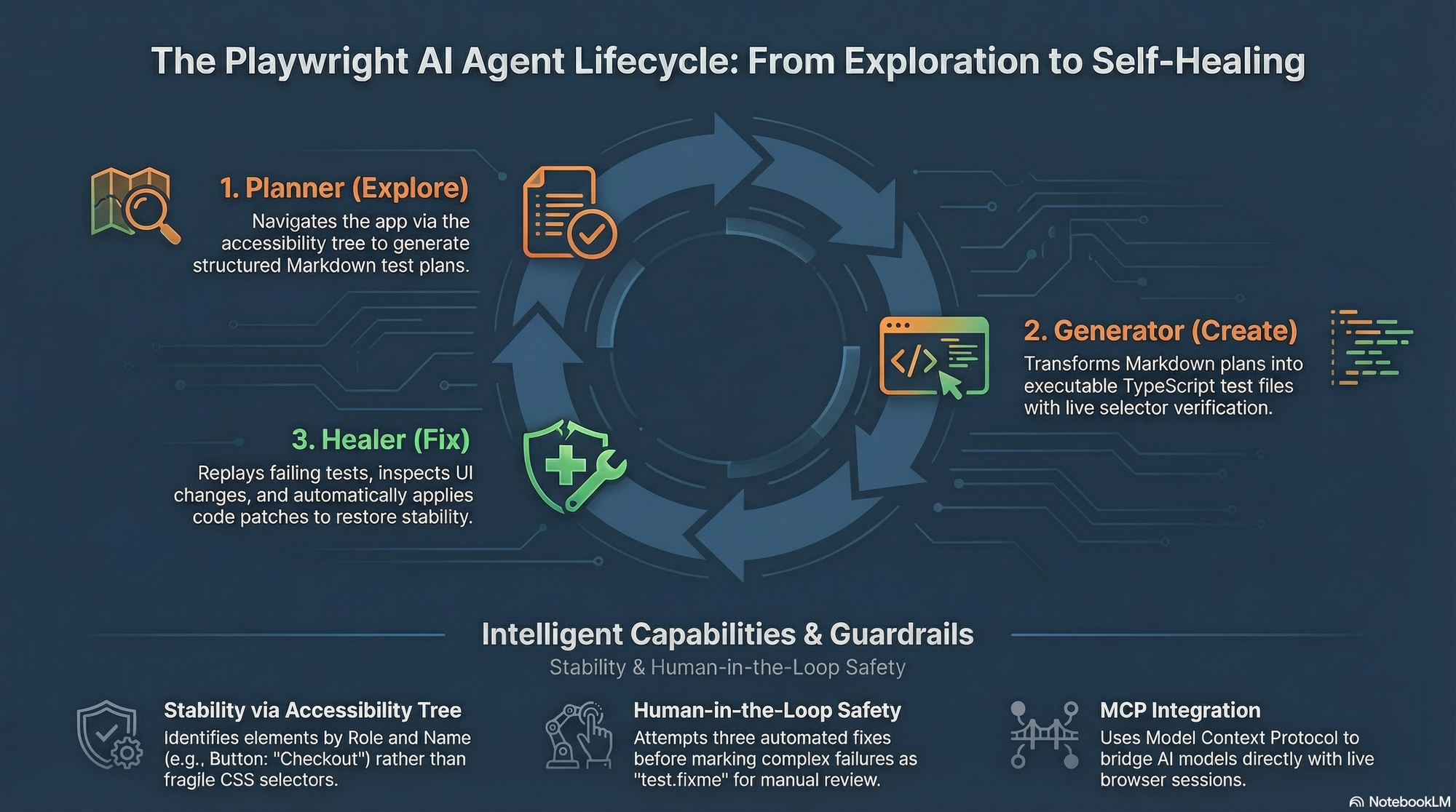
- The Power Trio : Planner, Generator, and Healer
To begin using the agentic workflow, teams initialize definitions using the npx playwright init-agents command. This populates the project with the necessary instructions to drive three distinct agents :
- The Planner : This agent explores the application to produce human-readable Markdown test plans from natural language requests. It utilizes "seed tests" to provide the initialization, global setup, fixtures, and environment context necessary to interact with the application
- The Generator : The Generator transforms Markdown plans into executable TypeScript files while live-verifying Semantic Locators and assertions against the running application. It uses the seed tests as a blueprint to ensure generated code follows existing project patterns.
- The Healer : When a test fails, the Healer replays the steps, inspects the current UI, and suggests automated patches for locators or wait adjustments. Beyond simple repairs, it classifies failures into three distinct buckets : Bug, Flaky, or UI Changes.
- Technical Edge : Why the Accessibility Tree Beats the DOM
Playwright's agents prioritize the Accessibility Tree over the raw DOM, which is the key to their superior stability. By stripping away "presentation markup" the agent receives a clearer signal on element roles, reducing token count by approximately 70%. Furthermore, v1.56 introduces Aria snapshots, allowing engineers to perform assertions directly against the accessibility tree state rather than volatile HTML structures.
- Quantifying the Impact : Slashing Maintenance by 95%
Data indicates that timing issues account for ~30% of flakiness, while unstable selectors contribute ~28%. While Self-Healing can reduce selector-based maintenance by 85% to 95%, it is not a silver bullet; teams must still apply engineering rigor to solve underlying timing problems.
When implemented correctly, this creates the "sandwich effect": an engineer can initiate a healing run, "grab a sandwich," and return to a suite that is either passing or clearly annotated with root-cause classifications. However, a staff-level perspective acknowledges the "Manual Review Tax". Even with high-performance healing, every AI-suggested repair requires human validation-often consuming 10-15 hours per sprint-to ensure the fix aligns with business logic.
- Field Guide for Model Selection and Performance
The ROI of agentic testing is heavily dependent on the underlying Large Language Model (LLM). Low-cost models frequently generate "AI slop" such as nonsensical waitForSelector strategies on elements that do not exist.
- Model Performance : For production-grade results, prioritize Opus 4.5+ or Codex 5.3. These models exhibit the reasoning required to handle complex DOM structures without generating invalid code.
- Speed vs. Context : Use LLaMA 3.1 (8B-instant) for high-speed inference. When paired with a GROQ LPU (Language Processing Unit), it achieves millisecond response times while handling the large context windows (150K tokens/min) required for deep browser analysis.
- Token Efficiency : While the Model Context Protocol (MCP) is excellent for interactive debugging, it consumes significantly more tokens (roughly 114k vs. 27k) than the Playwright CLI. Use the CLI for batch generation to minimize token burn.
- The "Logic Drift" Warning : Why Humans Stay at the Helm
A critical risk in autonomous testing is "Logic Drift" where an agent prioritizes making a test pass over validating the original intent. For example, a Healer might encounter two identical heading elements and "loosen" a regex pattern to allow the test to pass, potentially masking a UI bug where only one heading should exist.
To maintain a "Human-in-the-Loop" standard, the following requirements are non-negotiable :
- Patch Review : Every automated patch must be reviewed to ensure it does not hide legitimate application regressions.
- Intent Verification : Engineers must confirm the agent hasn't lowered the validation bar simply to achieve a "green" status.
- Backend Triage : If the Healer identifies a "Failed to fetch" error in the console logs, it should mark the failure as test.fixme rather than attempting a frontend code fix for a backend outage.
- Conclusion : The Future of Maintenance - Free Testing
The transition from DIY frameworks to autonomous platforms represents a fundamental shift in how we approach quality. By leveraging the Planner, Generator, and Healer, teams can move away from the manual labor of chasing flaky CI failures and refocus on high-level feature logic and strategic oversight. While AI significantly accelerates the authoring and healing cycles, the engineering "Manual Review Tax" remains the final check against the risks of logic drift, ensuring that speed never comes at the cost of reliability.